Cуть проекта — инструмент на базе ML для автоматизированного мониторинга и аналитики новостей в СМИ и соцсетях, оценки их тональности, классификации по тематикам сообщений и кластеризации инфоповодов для эффективного управления инфополем и снижения репутационных угроз.
Введение
В данном документе представлен успешный проект интеграции автоматизированной системы мониторинга и обработки новостей СМИ и социальных сетей, реализованный нашей командой для клиента — крупного медиааналитического агенства. Проект охватывал полный цикл разработки, начиная с фазы проектирования и заканчивая финальной стадией интеграции в рабочий процесс клиента и обучения пользователей. Результаты проекта - это сокращение времени на ручную обработку текстовых данных, оптимизацию расходов и улучшение качества предоставляемых услуг.
Клиент
Заказчик - Медиа Аналитическое Агенство в РФ
Крупное медиааналитическое агентство в России, с 2005 года предоставляющее услуги по мониторингу и анализу СМИ и соцмедиа для брендов, государственных корпораций и структур, малого и среднего бизнеса
Боль-Запрос
Высокая зависимость от ручного труда и высокой себестоимости проектов
→ Автоматизировать ручной и трудоемкий процесс анализа новостей и комментариев
Низкое качество ручной обработки
→ Увеличить качество анализа
Из-за высокой зависимости от ручного труда ограничены возможности принимать множество проектов
→ Дать автоматизированный инструмент для клиента, позволив масштабировать количество рабочих проектов
Описание проекта
Необходимо было разработать автоматизированный сервис для интеллектуальной обработки новостей в СМИ и сообщений в соцсетях. В основе разрабатываемого сервиса использовались модели машинного обучения (ML модели / Machine Learning модели) с использованием методов обработки естественного языка (NLP / Natural Language Processing):
Кластеризация новостей СМИ и сообщений соц. сетей
Оценка тональности сообщений
Определение тематик сообщений
Технический стек для разработки ML моделей - Python Data Science Stack (Python, PyTorch).
Продуктивизация моделей осуществлялась в виде REST API сервиса.
Также был разработан отдельный модуль для обучения / дообучения / переобучения моделей на языке Python.
Длительность проекта
Общая длительность проекта: 5 месяцев
Обследование и проектирование — 3-4 недели
Разработка функционала решения — 3 месяца
Внедрение и тестирование — 1 месяц
Поддержка
Команда
1 Project Manager
Data Science (DS) team:
— 1 DS Lead / NLP Lead — 2 опытных в области NLP Data Scientist
Разработка:
— Back-end Developer
Документация:
— Бизнес-аналитик / технический писатель
Стоимость реализации проекта
Общая стоимость проекта составила ~ 100k USD
Решение
Тональность
Техническое решение
Техническое решение включает разработку высоконадежного сервиса для анализа тональности текстов из различных источников, включая СМИ и социальные медиа. Мы реализовали это через Docker-контейнер, содержащий специализированную модель машинного обучения на базе Python и Pytorch. Контейнер развернут в облачной инфраструктуре Яндекса, обеспечивая гибкость и масштабируемость. Сервис обрабатывает входящие REST API POST запросы, анализирует тексты на наличие сущностей и возвращает точные и быстрые результаты, классифицируя тональность текстов как положительную, нейтральную или отрицательную.
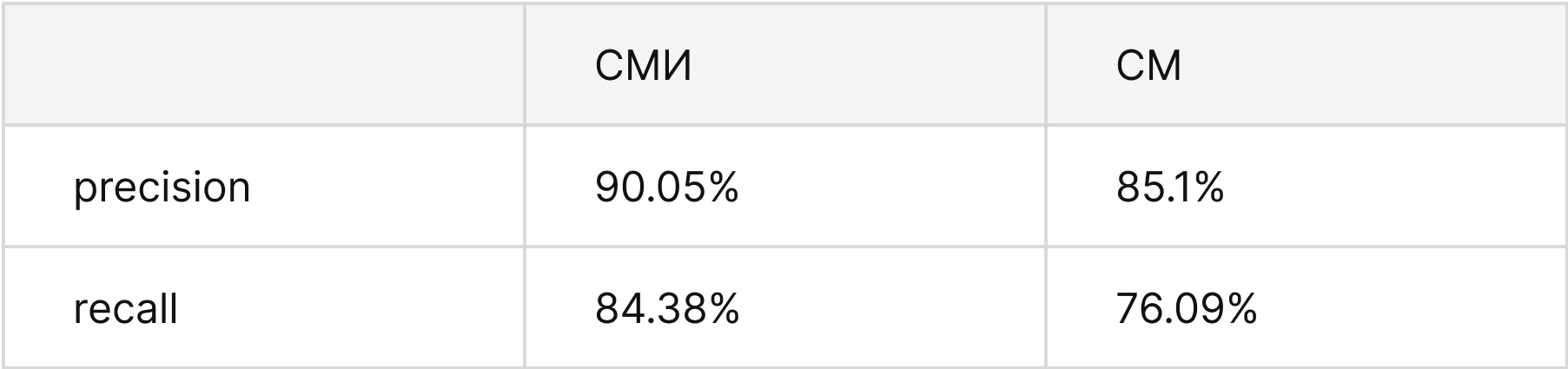
Сравнение предобученных моделей
Инфоповоды
Техническое решение
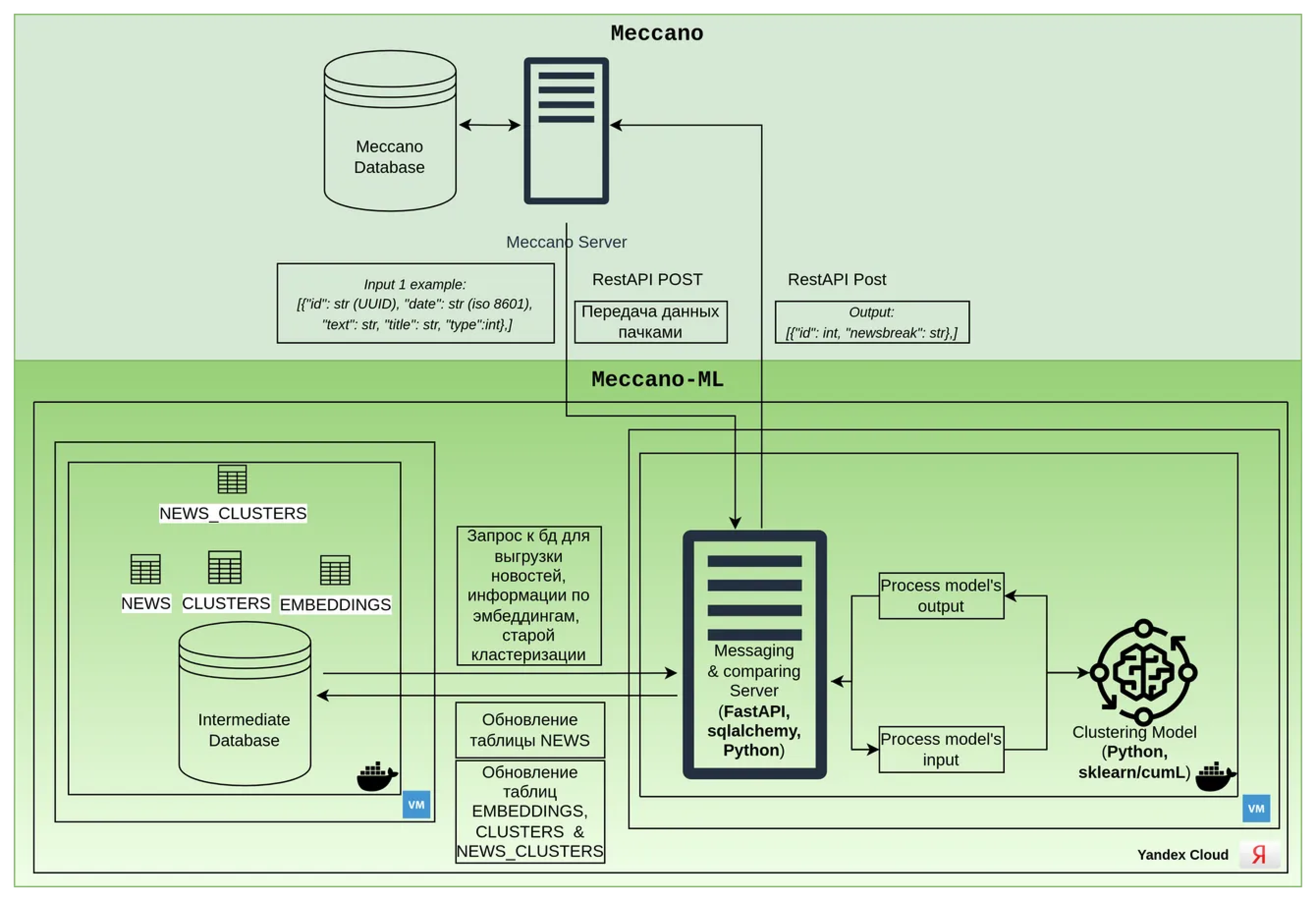
Meccano предлагает инновационный сервис для автоматического выявления информационных потоков из СМИ и социальных медиа. Решение реализовано в формате докер-контейнера, содержащего модель машинного обучения для точной кластеризации текстов. Контейнер развернут в облачной инфраструктуре Яндекса на выделенной виртуальной машине, обеспечивая высокую степень безопасности и надежности данных. В комплекс входит промежуточная база данных, управляемая командой разработчиков Meccano, а также асинхронная схема обработки данных через REST API для эффективного взаимодействия с внешними системами, включая передачу аналитических результатов информационных потоков.
Meccano предлагает передовой сервис для автоматического тегирования текстов из СМИ и социальных медиа.
Решение реализовано в виде докер-контейнера с специализированной моделью машинного обучения.
Контейнер размещен и запущен в облачной инфраструктуре Яндекса, обеспечивая высокую степень надежности и безопасности данных.
Сервис поддерживает синхронную обработку данных через REST API.
Модель обладает высокой производительностью, обрабатывая до 3 запросов в секунду на тексты длиной около 3000 символов.
Для работы модели требуется не более 12 ГБ видеопамяти и 12 ГБ оперативной памяти.
Проект включает модель машинного обучения для тегирования текстов, сервер сообщений для приема и отправки данных, а также модули предобработки и постобработки данных.
Решение поддерживает различные домены СМИ и социальных медиа, обеспечивая гибкость и точность в выдаче результатов.
Результат проекта
На стороне Заказчика (на серверном оборудовании либо на облачных ресурсах) развернут веб-сервис, в котором продуктивизированы три ML модели для обработки текстовых данных.
Разработан модуль обучения моделей в виде скрипта на Python.
Разработана базовая документация с описанием полученных моделей, архитектуры сервиса и API.
Точность распознавания тематик — 80+%, определения тональности — 92+%
Политика, религия, экономика, финансы
Бизнес, общество
Бизнес эффект
Следующие шаги
План на второй этап
На этапе 1.1 проекта предусмотрено дообучение и улучшение моделей анализа тональности и тэгирования на основе обратной связи после тестирования и завершения сбора данных. Эти работы планируется провести параллельно в течение одного месяца.
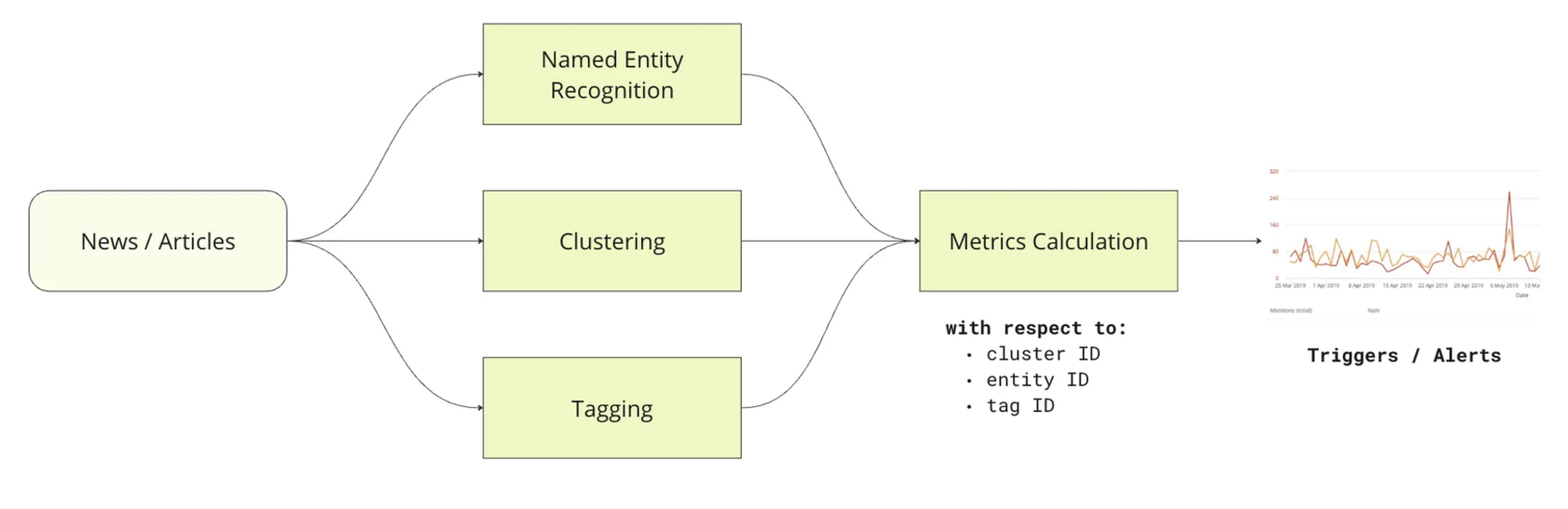
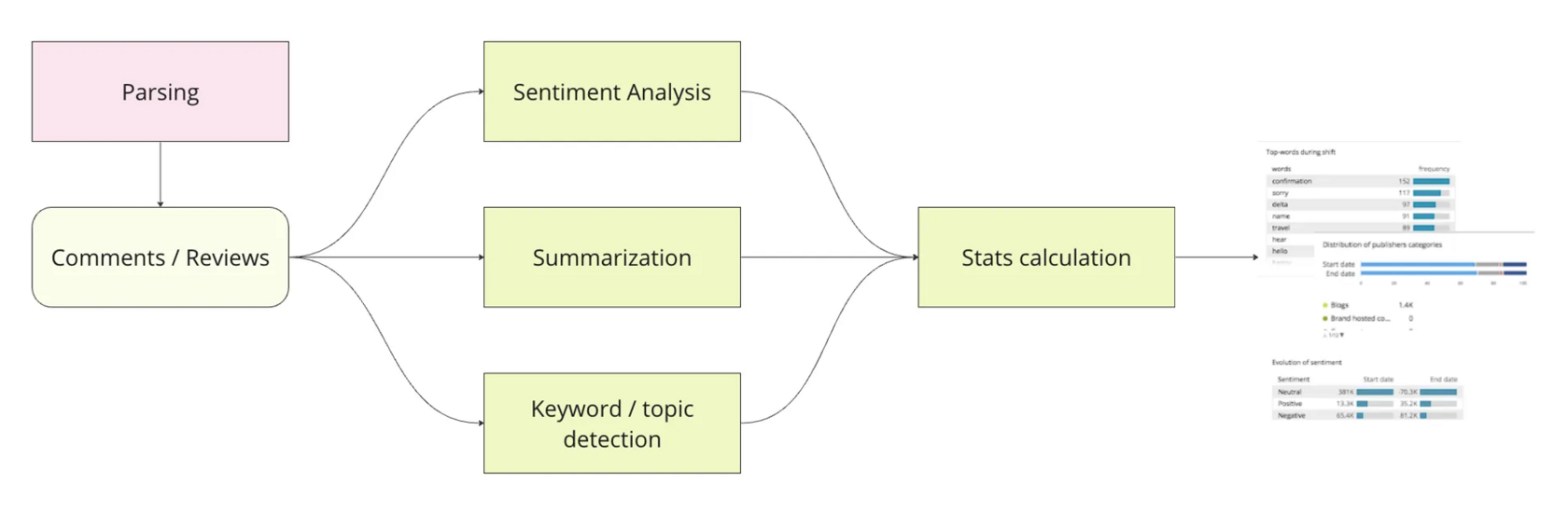
На этапе 2, основное внимание будет уделено анализу трендов и управлению репутацией компании. В рамках анализа трендов планируется мониторинг и реакция на активность в медиаполе, что займёт два месяца. В работе с репутацией будут использованы методы извлечения ключевых слов из отзывов, автоматической суммаризации обзоров и анализа тональности, также с двумесячным сроком реализации.
Автоматизация обработки новостей СМИ и сообщений соцсетей